





.png)

%20(2).png)
%20(2).png)
Helpful summary
Overview: We explain how to fix the 'Blocked by robots.txt' error in Google Search Console. Fixing this error is key for website accessibility and visibility in search results.
Why you can trust us: Our case studies show how we successfully fixed technical SEO issues such as 'Blocked by robots.txt' which resulted in faster website indexing for our clients, enhancing their visibility in SERPs.
Why this is important: By fixing these errors, you can increase your website's traffic, make it faster for search engines to find your content, and ultimately boost your revenue.
Action points: We suggest checking and fixing your robots.txt file errors, using Google's Robots.txt Testing Tool, and keeping your robots.txt file up-to-date.
Further research: We recommend keeping up with SEO trends and regularly reading SEO blogs and case studies to prevent and manage these errors.
Need help in resolving the 'Blocked by robots.txt' error in Google Search Console?
Website accessibility is a crucial factor in ensuring a good online presence and reaching a broader audience. If you're looking for scalable solutions tailored to large organizations, discover how top enterprise SEO companies drive consistent organic growth at scale. However, there can be instances when certain pages of your website become inaccessible due to restrictions set by a robots.txt file.
This can cause such pages to drop from Google's index, affecting your website's visibility in search results.
But don't worry! This Embarque guide will walk you through the steps to identify and fix issues related to the 'Blocked by robots.txt' error in Google Search Console, ensuring your website is crawlable and indexed properly by search engines.
Why listen to us?
Encountering a 'Blocked by robots.txt' error in Google Search Console can be a major hurdle for small businesses aiming to enhance their online presence. At Embarque, we've mastered addressing this issue. For instance, our work with Stagetimer, a SaaS for event management, is a testament to our expertise. Initially, Stagetimer's website traffic was meager, with only 40-50 visitors per month. With our SEO strategy, they witnessed a surge to over 8,838 monthly visitors, significantly boosting their revenue.
Another compelling example is our project with a technical SaaS targeting a niche market. They experienced a staggering 60x increase in monthly organic traffic within a year of employing our linkbuilding techniques, starting from a mere 27 visitors per month to reaching 7,495 visitors, substantially improving their revenue.
These case studies demonstrate our direct experience and success in tackling SEO challenges like the 'Blocked by robots.txt' error, leading to significant traffic and revenue growth for small businesses.
What does ‘Blocked by robots.txt’ in Google Search Console mean?
When you see the ‘Blocked by robots.txt’ error message in Google Search Console, it means that Googlebot, which is Google's web crawling bot, cannot access certain pages on your website. This happens because your site's robots.txt file has instructions that limit Googlebot's access.
In simpler terms, it means that Google is unable to view specific pages on your website due to the rules set in the robots.txt file. If these pages are intended to be indexed and visible in search results, the ‘Blocked by robots.txt’ error could pose a problem.
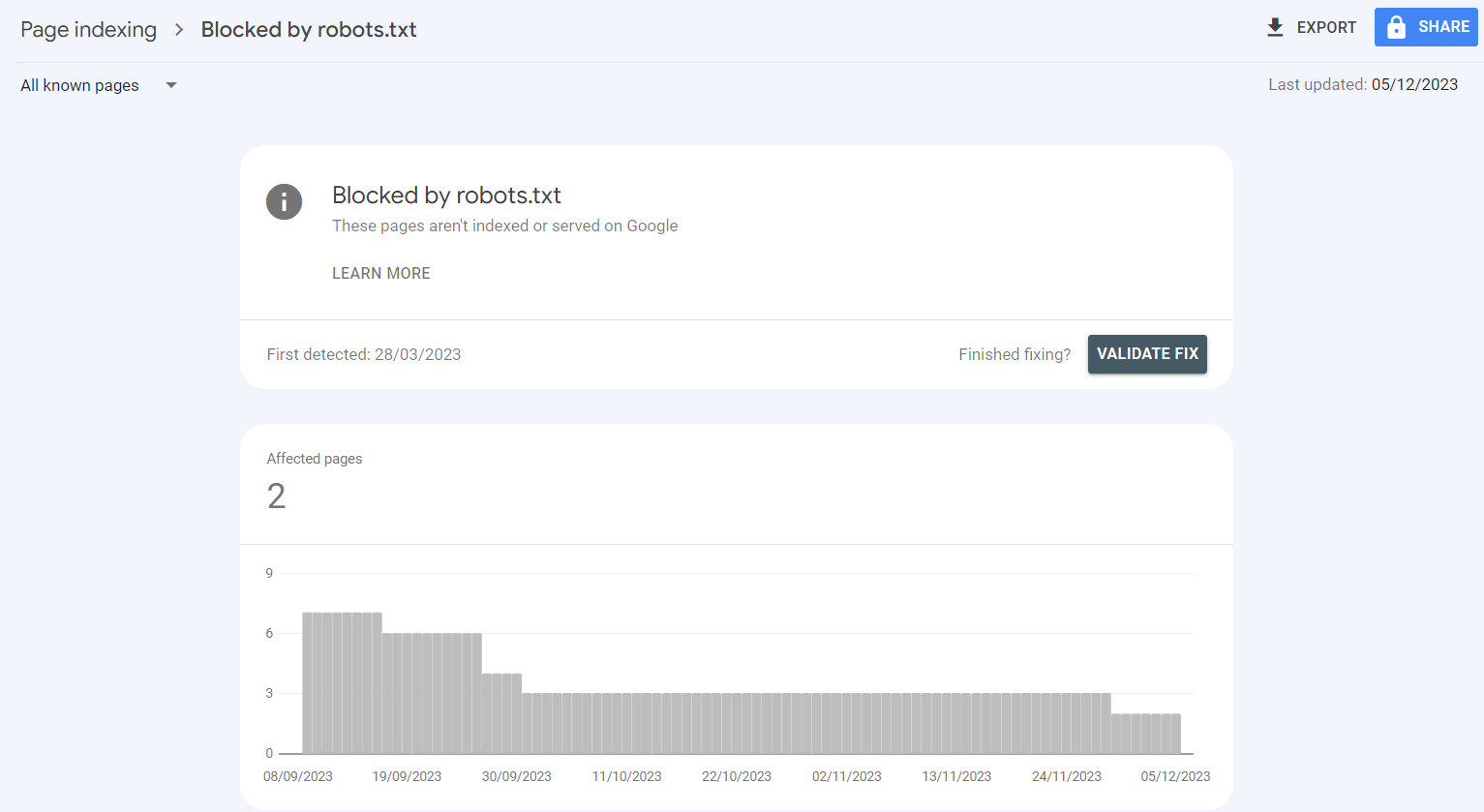
Common reasons for the ‘Blocked by robots.txt’ error
- Incorrect configuration: The most common reason for this error is an incorrect configuration in the robots.txt file. This can happen if you use the 'Disallow' directive improperly, unintentionally blocking important pages from being crawled.
- Overly broad disallow directives: Sometimes, broad patterns in the ‘Disallow’ directive may inadvertently block more pages than intended. For example, disallowing a directory could unintentionally block access to all subdirectories and files within it.
- Legacy or outdated rules: In some cases, robots.txt rules that were added for a previous version of the website may no longer be relevant but still exist in the file, inadvertently blocking current content.
- Manual errors: Simple typos or syntax errors in the robots.txt file can lead to unintentional blocking. For instance, a missing slash ("/") or an extra character can change the scope of what is disallowed.
- Third-party SEO plugins or tools: Sometimes, SEO plugins or tools that automatically generate or modify robots.txt can create rules that block important content without the site owner’s knowledge.
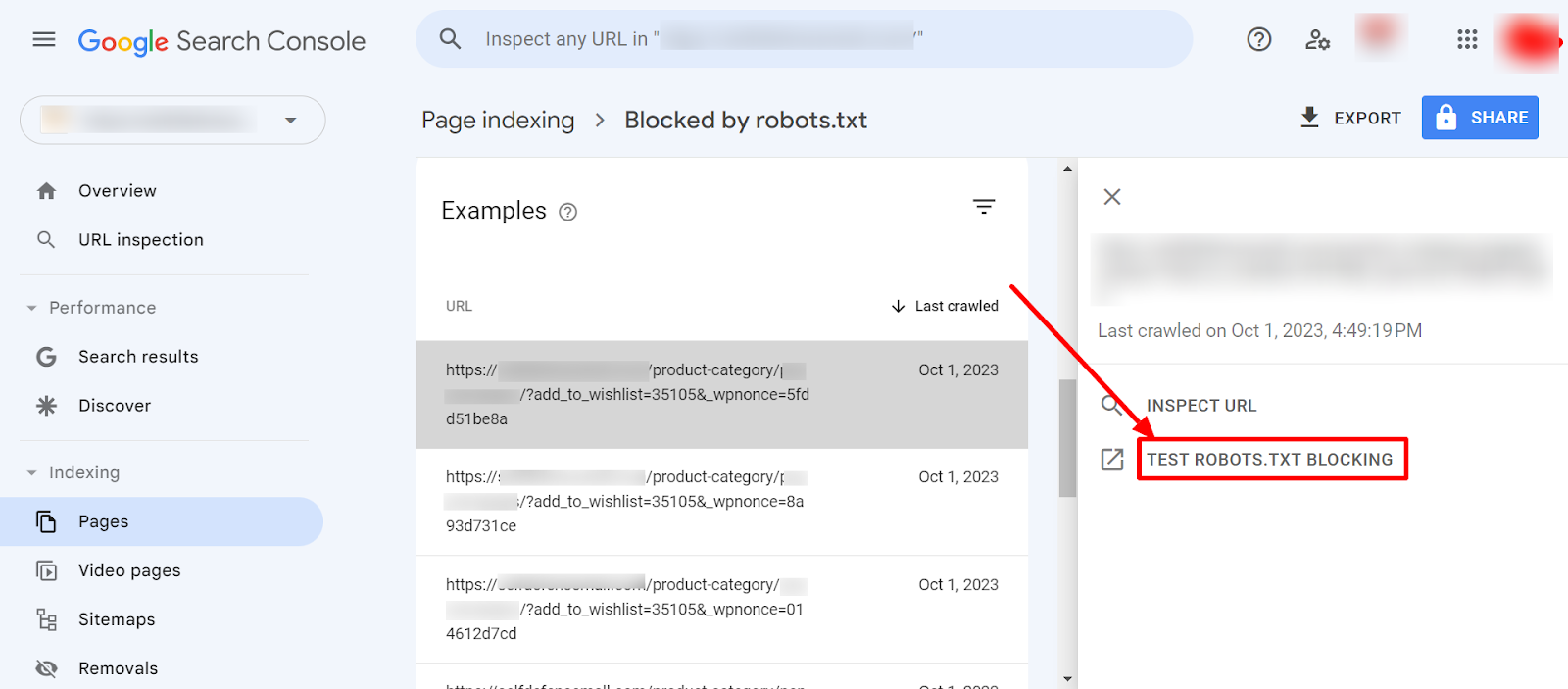
How to identify the 'Blocked by robots.txt' in Google Search Console
To identify the 'Blocked by robots.txt' error in Google Search Console, follow these steps:
- Log in to Google Search Console.
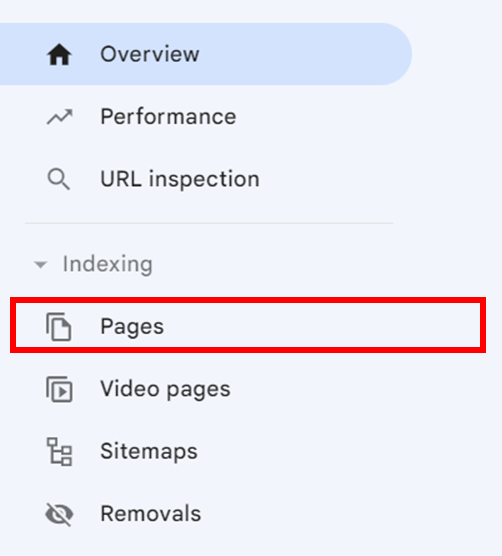
- In the left navigation panel, under Indexing, click on Pages.
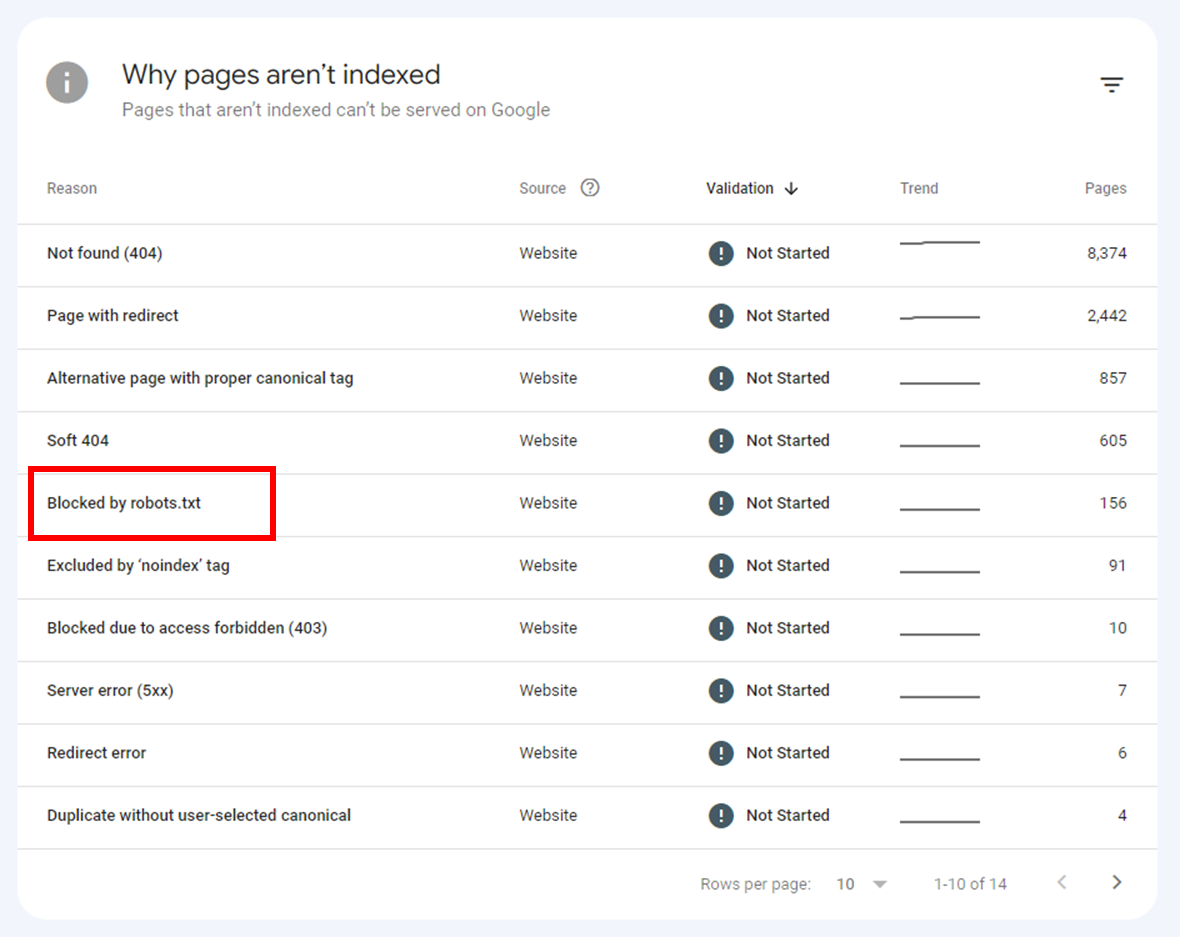
- Scroll down under Why pages aren’t indexed.
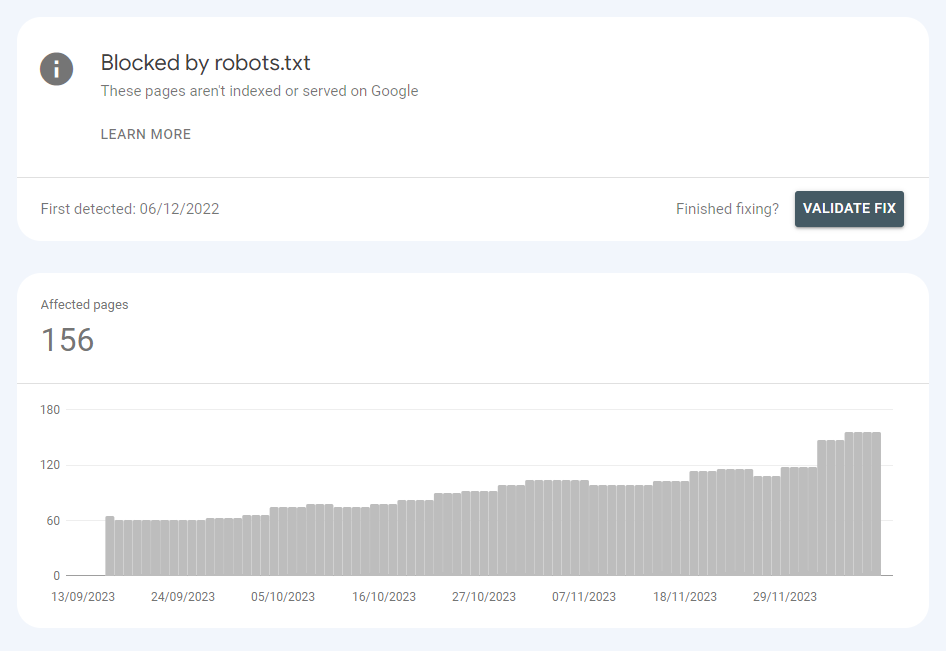
- Click on Blocked by robots.txt.
Step-by-step guide to fixing the 'Blocked by robots.txt' error
Correcting the robots.txt file configuration
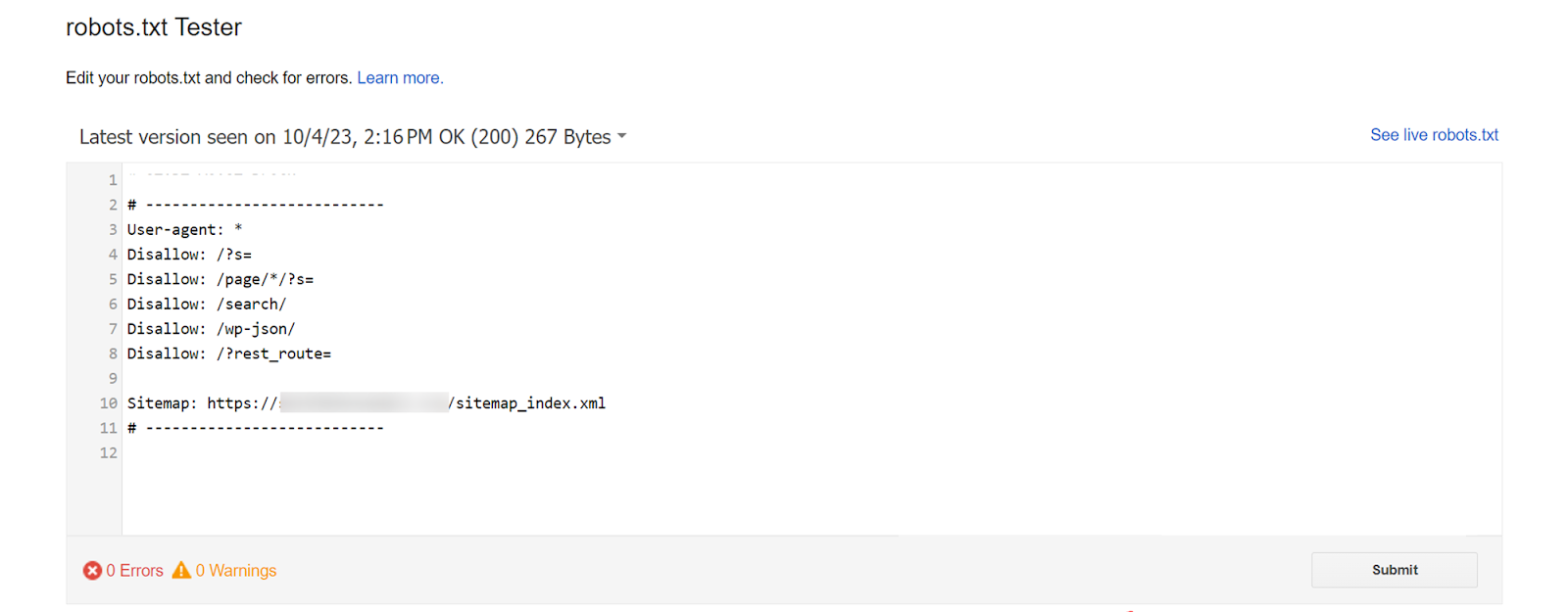
Step 1: Locate your robots.txt file
Your robots.txt file is typically located at the root of your website (e.g., https://www.yourwebsite.com/robots.txt). Verify the file's presence and location by entering your website's URL followed by /robots.txt in your browser.
Step 2: Review and edit the file
Access the robots.txt file on your web server. This might require FTP access or a file manager tool provided by your web hosting service. Review the directives in the file, especially lines with "Disallow:" which indicate the paths that are blocked.
Correct any errors or overly broad directives. For instance, change Disallow: / (which blocks the entire site) to more specific directories or pages you want to exclude.
Step 3: Update the robots.txt file
After making the necessary changes, save the updated robots.txt file. Upload the updated file to the root directory of your website, replacing the old one.
Step 4: Verify the changes
After uploading, recheck https://www.yourwebsite.com/robots.txt in your browser to ensure the changes are live.
We will now use Google robots.txt Tester to test and submit the page for recrawling and indexing.
How to use Google robots.txt tester
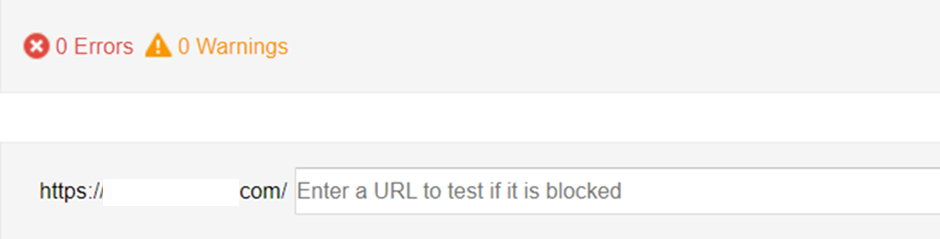
Step 1: Access the tool
In Google Search Console, navigate to the 'robots.txt Tester' tool found under the 'Crawl' section.
Step 2: Enter the URL
The tool automatically loads the content of your site's robots.txt file. Enter the URL of a page on your site in the text box at the bottom of the tool.
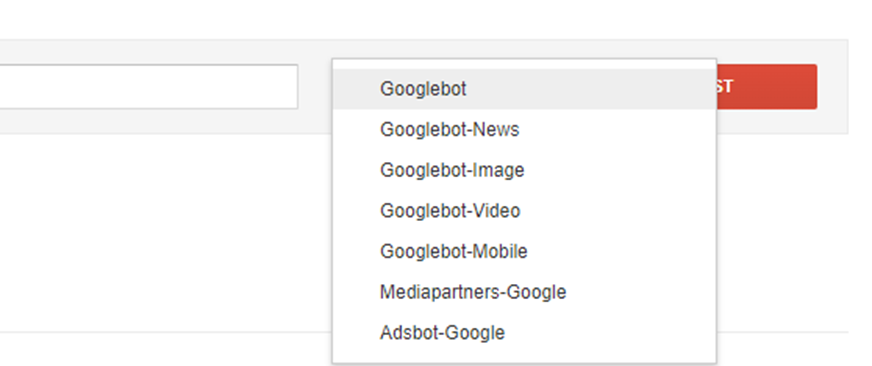
Step 3: Select the user-agent
Choose 'Googlebot' from the user-agent drop-down to simulate how Googlebot interprets your robots.txt file.
Step 4: Run the test
Click the 'Test' button to check if Googlebot can crawl the page. The tool will show whether the page is 'Allowed' or 'Blocked' by the current robots.txt rules.
Step 5: Edit and debug
If the tool indicates that a page is blocked, you can modify the robots.txt rules directly in the tool for testing purposes. Once you find a rule that allows the page, apply this change to your actual robots.txt file on your server.
Step 6: Submit for Re-indexing
Once you've corrected your robots.txt file and confirmed the changes with the tester tool, use Google Search Console to request re-indexing of the affected pages.
Best practices to prevent the 'Blocked by robots.txt' error and manage robots.txt files
Regular reviewing and monitoring
- Schedule regular checks: Implement a routine (monthly or quarterly) to review your robots.txt file, particularly after significant updates to your website.
- Monitor Google Search Console: Use Google Search Console to track interactions with your robots.txt file and stay alert to crawl errors or warnings.
Utilize tools for effective management
- Leverage SEO plugins and tools: Employ SEO tools that can help in tracking and managing your robots.txt file, providing alerts for potential issues.
Clarify your directives
- Use specific directives: Ensure ‘Disallow’ directives in your robots.txt file are precise to prevent accidental blocking of crucial content.
- Comment on changes: Include comments (using #) in your robots.txt file to document the purpose of each directive for future clarity.
Learn from personal and industry experience
- Refer to SEO case studies: Regularly consult SEO blogs and case studies for insights on common robots.txt misconfigurations.
- Stay informed about SEO trends: Keep up-to-date with the latest SEO trends and guidelines to align with evolving search engine algorithms and best practices.
Remember, maintaining a well-organized and correctly configured robots.txt file is essential for optimal website crawling and indexing by search engines
Master Google Search Console with Embarque
Our guide provides detailed insights into resolving the 'Blocked by robots.txt' error in Google Search Console, a common issue that can hinder a website's SEO performance. We’ve underscored the importance of understanding the function of robots.txt files, identifying and correcting the directives causing the blockage, and ensuring that essential pages are not inadvertently disallowed.
For website owners and SEO professionals struggling with this issue, Embarque offers specialized solutions tailored to address and rectify 'Blocked by robots.txt' errors. With a focus on enhancing website accessibility for search engines, our expertise in SEO optimization can be instrumental in improving your site's visibility and search ranking.
To discover how Embarque can assist in resolving your website's 'Blocked by robots.txt' issues and enhance your online search performance, visit our website or get in touch for a bespoke consultation.
Let Embarque guide you in optimizing your site's SEO potential, ensuring that your valuable content is fully accessible to search engines and your target audience.
.png)




